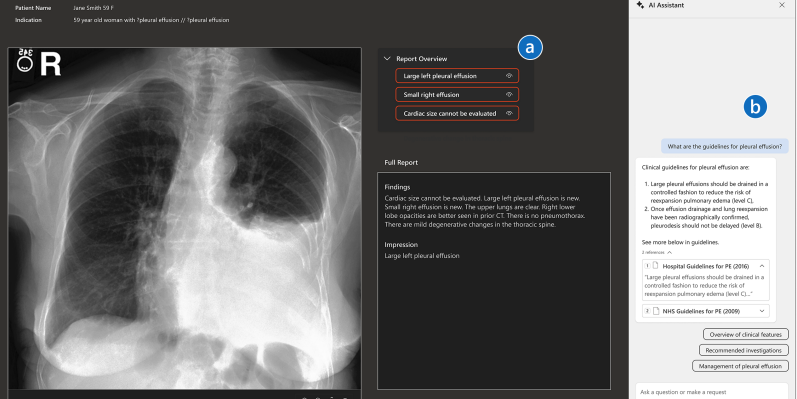
Large Language Models (LLMs) for radiology are rapidly gaining popularity in research, and some of the first use cases are now being adopted clinically. This article aims to integrate LLMs with visual encoders (vision-language models (VLMs)) and presents four innovative applications: Draft Report Generation, Augmented Report Review, Visual Search and Query, and Patient Imaging History Highlights. The research team addresses key challenges in radiology workflows. The study, which involved 13 radiologists, found the VLM concepts to be valuable, highlighted the importance and opportunities for VLMs in radiology, and discussed the implications of integrating VLM capabilities into the field.
Read full study
ABSTRACT
Recent advances in AI combine large language models (LLMs) with vision encoders that bring forward unprecedented technical capabilities to leverage for a wide range of healthcare applications. Focusing on the domain of radiology, vision-language models (VLMs) achieve good performance results for tasks such as generating radiology findings based on a patient’s medical image, or answering visual questions (e.g., “Where are the nodules in this chest X-ray?”). However, the clinical utility of potential applications of these capabilities is currently underexplored. We engaged in an iterative, multidisciplinary design process to envision clinically relevant VLM interactions, and co-designed four VLM use concepts: Draft Report Generation, Augmented Report Review, Visual Search and Querying, and Patient Imaging History Highlights. We studied these concepts with 13 radiologists and clinicians who assessed the VLM concepts as valuable, yet articulated many design considerations. Reflecting on our findings, we discuss implications for integrating VLM capabilities in radiology, and for healthcare AI more generally.